Postgres-redis Extension in Rust
The main objective of this project was to understand some Postgres internal and also get handy with rust via building a Postgres extension that allows tracking a particular table column and using the values in that column to populate our Redis store.
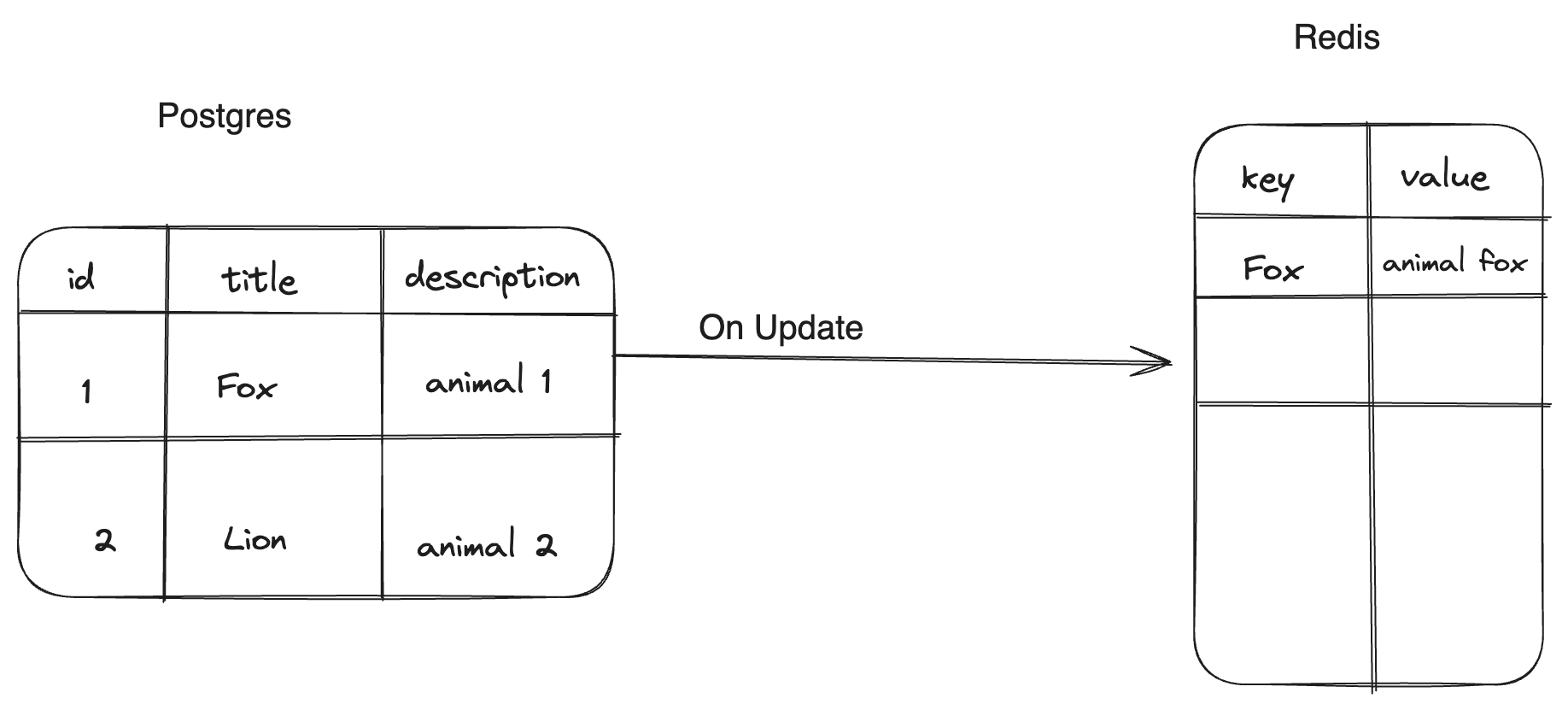
The main scope is to track any update to a specific table, e.g. using the image above, We have a table with three columns id, title, and description. Let’s assume we want to track this table and build a Redis store where column title values are the keys and column description values will be the Redis values
Note: this article will be more about Postgres than Rust, hence you are meant to have at least an idea about rust.
Update Test SET description = 'animal fox' where title = 'Fox'
the following are the main criteria:
- identify the table to be tracked e.g
test - identify the columns in the table that will serve as the Redis keys and values
- whenever we have an update query that has our table in it and the where clause contains our key column, obtain the update and send it to redis
Table of Contents
- Install Pgrx and Postgres db
- Setting up custom variables using GUC
- Postgres Hook
-
Obtaining Redis key- Planner Hook
-
Obtaining Redis value - Executor end
-
Background writer and shared memory
- Running the code
Install Pgrx and Postgres db
To get started let’s install postgres db; the easiest way to install postgres db without any complicated issues for the project is to install via postgres.app.
Once Postgres db is installed, we can install pgrx, first make sure you have rust and cargo installed.
$ cargo install --locked cargo-pgrx
once the installation is done, we can then initialize pgrx to properly configure the pgrx development environment
$ cargo pgrx init
Note: If you are a Mac user and you have any issue with the initialization try running brew install pkg-config icu4c
Once the initialization is done, we can go ahead to create the project workspace
$ cargo pgrx new postgres-redis
this initializes the workspace with a boilerplate to get started with.
$ ls postgres-redis
Cargo.toml postgres_redis.control sql src
For more details about pgrx command check here
Setting up custom variables using GUC
Based on the criteria we’ve set for this extension implementation we need a way to set up the required configs to get the extension working.
We therefore make use of the Grand Unified configuration (Guc). Guc enables us to control postgres from different levels:
PGC_INTERNAL
PGC_POSTMASTER
PGC_SIGHUP
PGC_SU_BACKEND
PGC_BACKEND
PGC_SUSET
PGC_USERSET
For this project, we would love to enable postgres control from PGC_USERSET, by control, I mean setting up config/env variables that control how postgres behaves. Normally, postgres config can be set before initializing your db via postgresql.conf, but with the PGC_USERSET we are flexible and dynamic enough, such that we can set a config dynamically via
ALTER SYSTEM SET postgres_redis.table TO 'test';
This will update postgresql.auto.conf with this new update and the config gets updated at run time.
To know more about the other control levels in clear detail check GucContext
Going ahead with the specification above, we will create a new file called gucs.rs under src/. Each config variable definition follows this basic steps
use pgrx::*;
use std::ffi::CStr;
pub static PGD_REDIS_URL: GucSetting<Option<&'static CStr>> =
GucSetting::<Option<&'static CStr>>::new(None);
pub fn init() {
GucRegistry::define_string_guc(
name: "postgres_redis.redis_url",
short_description: "Redis URL",
long_description: "The url of the redis server to send the data to.",
setting: &PGD_REDIS_URL,
context: GucContext::Userset, // defined the control level here
flags: GucFlags::default(),
);
}
Firstly, we import the necessary packages; for std::ffi:cstr, since the extension is also interacting with C code from Postgres via an abstraction in pgrx we will make use of some Foreign function interface utils a lot and one of them is the null pointer char char * in c which is now represented has CStr.
We create a static variable and a static lifetime for each of these config variables and then declare an initialization function to define each of the config variables via GucRegistry::define_string_guc this function will be called for each of the proposed variables and in it we declare the name of the variable and how it should be specified in the config file, also contains the description of the variable, setting to point the variable to our defined static variable, also we specified the context to which this variable can be created.
pub static PGD_REDIS_URL: GucSetting<Option<&'static CStr>> =
GucSetting::<Option<&'static CStr>>::new(None);
pub static PGD_REDIS_TABLE: GucSetting<Option<&'static CStr>> =
GucSetting::<Option<&'static CStr>>::new(None);
pub static PGD_KEY_COLUMN: GucSetting<Option<&'static CStr>> =
GucSetting::<Option<&'static CStr>>::new(None);
pub static PGD_VALUE_COLUMN: GucSetting<Option<&'static CStr>> =
GucSetting::<Option<&'static CStr>>::new(None);
pub fn init() {
GucRegistry::define_string_guc(
"postgres_redis.redis_url",
"Redis URL",
"The url of the redis server to send the data to.",
&PGD_REDIS_URL,
GucContext::Userset,
GucFlags::default(),
);
GucRegistry::define_string_guc(
"postgres_redis.redis_table",
"Table name",
"The table name to track for changes.",
&PGD_REDIS_TABLE,
GucContext::Userset,
GucFlags::default(),
);
GucRegistry::define_string_guc(
"postgres_redis.key_column",
"Table column name",
"The column name whose value will be used as the key in the redis hash.",
&PGD_KEY_COLUMN,
GucContext::Userset,
GucFlags::default(),
);
GucRegistry::define_string_guc(
"postgres_redis.value_column",
"Table column name",
"The column name whose value will be used as the value in the redis hash.",
&PGD_VALUE_COLUMN,
GucContext::Userset,
GucFlags::default(),
);
}
Now we have the variables defined, we will discuss how to call this variable and make use of them later in this article
Postgres Hook
If we open the src/lib.rs we will see some boilerplate code to get us started. the code imports some of the necessary modules needed and also creates a Postgres sql function and includes a test for us.
For example, just using the provided function
#[pg_extern]
fn hello_postgres_redis() -> &'static str {
"Hello, postgres_redis"
}
[pg_extern] is a macro that helps write the sql function query CREATE OR REPLACE FUNCTION .... via the hello_postgres_redis, but unfortunately we won’t discuss in details how to create functions.
Well, we should be able to compile successfully and initialize our extension, and then call the hello_postgres_redis() function
build and run the code using pg14
$ cargo pgrx run pg14
postgres_redis=#
and then initialize the extension
postgres_redis=# create extension postgres_redis;
CREATE EXTENSION
postgres_redis is the name of our crate library, and then make a call to the sql function
postgres_redis=# select hello_postgres_redis();
hello_postgres_redis
-----------------------
Hello, postgres_redis
(1 row)
postgres_redis=#
The result above is the current state of our code.
Our main focus is to create hooks that help interfere with our code at different junctions needed;
- intercept the postgres process during Query planner (before query optimization ), to fetch our Redis key from the specified table and column
- Intercept postgress process during executor run, so has to get customized data returned from
selectquery - intercept postgress process when the executor is done, to fetch our redis key value
- Intercept Postgres process during commit, so has to save the data (key and value) fetched
Don’t worry, if you are not cleared each stage of interception, we will discuss more about them in subsequent sections of this article.
Before we can start initializing each of the interception stages, we need to set the basic layout of our hooks
use pgrx::{prelude::*, register_hook, HookResult, PgHooks};
// define custom data fields here for use accross our hooks
struct PRHook { }
// define custom hooks has method
impl PgHooks for PRHook { }
static mut HOOK: PRHook = PRHook {} // create hook variable
// function to register our hook and initialize various utilities needed
pub unsafe extern "C" fn _PG_init() {
// intializae utilities
register_hooks(&mut HOOK); // register hook
}
First, we created a struct PRHook, where we can create various fields that can be passed around in our custom hooks. Custom hooks definition are implemented has method in impl PgHooks for PRHook, after which the hooks is initialized and register as hooks in _PG_init
For this article, we will need to declare some fields in PRHook to store our custom variables
struct PRHook {
update_receiver: Option<UpdateDestReceiver>, // store data from executor end intersecting update queries
where_clause_receiver: Option<(String, String)>, // store values to be use has redis key
table: Option<String>, // store the table name extracted from the config
key_column: Option<String>, // store the column whose value will be use as redis key
value_column: Option<String>, // store the column name whose value will be use as redis value
keep_running: bool, // flag if table name is found or not in the query processs
}
and here is the blueprint of our hooks, we will discuss more about them in subsequent sections
impl PgHooks for PRHook {
fn planner() {}
fn excutor_end() {}
fn commit() {}
fn abort() {}
}
Now we have the basic structure of the hooks that will be implemented to get the work done. Next, we need to create the Hook struct variable and then initialize it in _PG_init
static mut HOOK: PRHook = PRHook {
update_receiver: None,
where_clause_receiver: None,
table: None,
key_column: None,
value_column: None,
keep_running: true,
};
and then create an init function comprising of fetching the necessary config variables and then registering the hook.
To fetch Guc variables we first need to import our gucs module and then fetch each of the config variables e.g
pub mod gucs
unsafe fn init_hook() {
// check if the env variable is not empty
if gucs::PGD_REDIS_TABLE.get().is_none() {
log!("Table name is not set");
return;
}
// the table value which is &str
let table_name = gucs::PGD_REDIS_TABLE
.get()
.unwrap()
.to_str()
.expect("table name extraction failed");
//......... other variables are ectracted the same way has table_name........
// convert the reference string to a Owned string
// and store in Hook.table
HOOK.table = Some(table_name.to_string());
// register the hook
register_hook(&mut HOOK);
}
The above code block shows how we obtain the config variables and then initialize the hook variable using register_hook. also note that we make use of unsafe; we will use this a lot, it helps us to work with raw pointer a lot.
We can now formally initialize how guc variable and init_hook
#[pg_guard]
pub unsafe extern "C" fn _PG_init() {
gucs::init();
init_hook();
}
unsafe extern "C" function is to tell that this function will be called in a c environment after it’s compiled to a shared library and linked from C. To learn more about unsafe check this rust book chapter
Obtaining Redis key - Planner Hook
We’ve set up the structure, and the right time to start implementing our hooks method. First, we need to fetch the value from the column we specify to be our key column. What do we mean by key column and what is the visual representation of this?
I will explain this using the example we started with from the beginning
Update Test SET description = 'animal fox' where title = 'Fox'
imagine we’ve chosen title to be the column we want its value to be our key, so whenever there is an update, we want to intercept this query has shown above hence we need a way to
- identify if the column we want is present in the query
- if the column is detected in the query, extract its value as a key e.g
Foxis the value and will be our redis key. - then store the column name and its value in
where_clause_receiver. - if a column or table is not found, we prevent the postgres from processing any code from us.
To achieve the specified steps, we are going to implement a planner hook.
fn planner(
&mut self,
parse: PgBox<pg_sys::Query>,
query_string: *const std::os::raw::c_char,
cursor_options: i32,
bound_params: PgBox<pg_sys::ParamListInfoData>,
prev_hook: fn(
parse: PgBox<pg_sys::Query>,
query_string: *const std::os::raw::c_char,
cursor_options: i32,
bound_params: PgBox<pg_sys::ParamListInfoData>,
) -> HookResult<*mut pg_sys::PlannedStmt>,
) -> HookResult<*mut pg_sys::PlannedStmt> {}
Don’t be bothered about the verbose list of function args and their type, for this implementation our main focus parse: PgBox<pg_sys::Query> and prev_hook callback.
The parse arg is a Query type and why are using this, doing query processing, postgres converts each of this query and sub-queries statements to a query tree, this query tree is a Data structure defined in parsenode.h
In this query table, we would only be making use of two fields for our exploration
typedef struct Query
{
List *rtable; /* list of range table entries */
FromExpr *jointree; /* table join tree (FROM and WHERE clauses) */
} Query;
The rtable fields contains list of tables, from here we can detect if the table we specify in our config is present in the query.
The jointree contains the data structure needed to generate our key from the Where clauses. The following image depicts the structure of the query tree
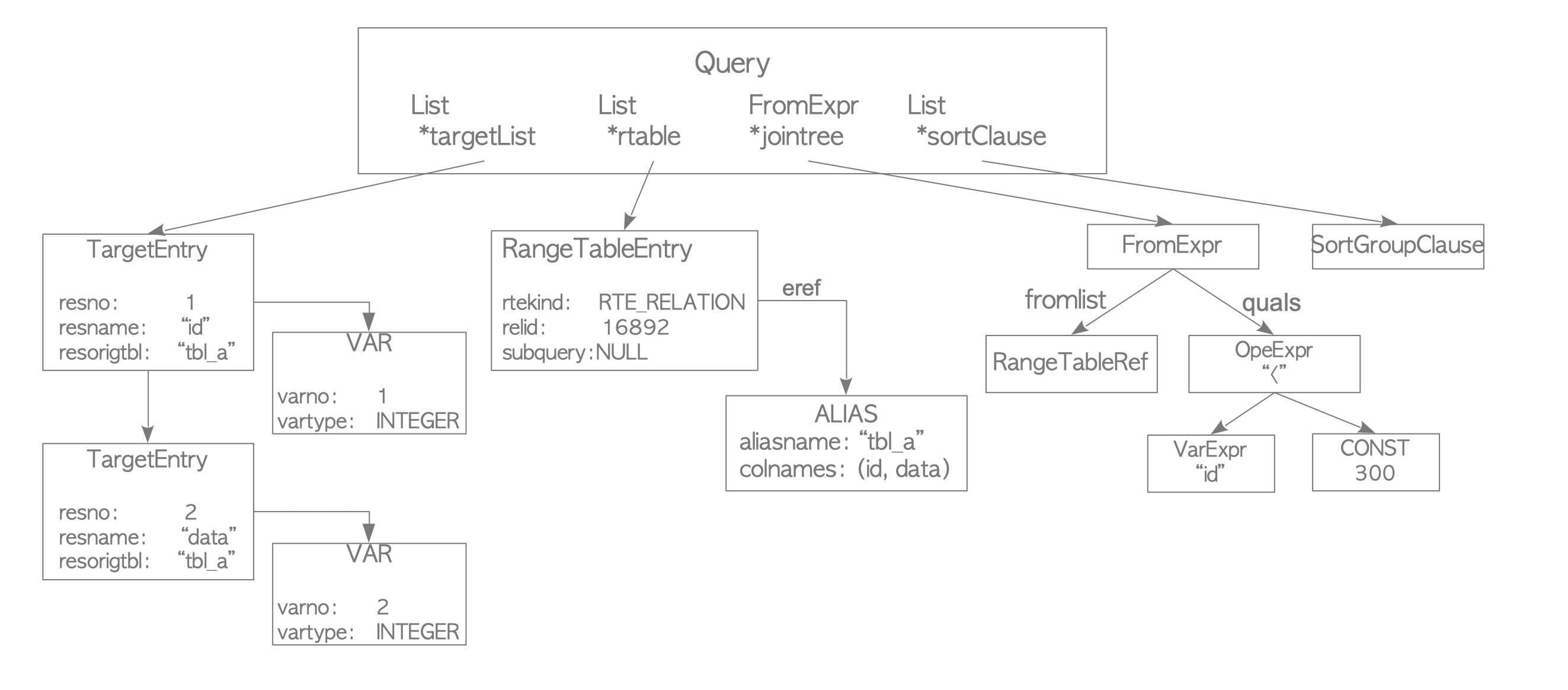
source: The internal of postgres
Focusing on the * jointree contains FromExpr node and this contains quals node which has Opexpr node and then our main aim will be to fetch the VarExpr which will be the column name and then we fetch the CONST which is our key.
Ok, back to code; First we need to check if this query statement contains our table, and create a file src/utils.rs. we will create a function that takes in rtable and then table_name we are looking for
pub fn is_contain_table(table_lists: *mut List, expected_table_name: &str) -> bool {
let mut result = false;
// code goes here
result
}
Since table_lists has type *mut List, this shows it is a raw pointer hence we will need to make use of unsafe to work with this
pub fn is_contain_table(table_lists: *mut List, expected_table_name: &str) -> bool {
let mut result = false;
unsafe {
let mut length = 0;
if !table_lists.is_null() {
length = table_lists.as_ref().unwrap().length;
}
for i in 1..=length {
let table_entry = *rt_fetch(i as u32, table_lists);
if table_entry.relkind as u8 != RELKIND_RELATION {
continue;
}
let table_data = *table_entry.eref;
let name = CStr::from_ptr(table_data.aliasname);
let name = name
.to_str()
.expect("Failed to convert Postgres query string for rust");
if name == expected_table_name {
result = true;
break;
}
}
}
result
}
table_lists.as_ref().unwrap().length we dereference the pointer and get the length of the list and then loop through it, remember we said rtable is a list of tables. for subqueries, we will have multiple tables (relations), but for our example, we should have one.
To get the rt_fetch takes in an index and the rtable list. it accesses the rtable per index and returns the table entry RangeTblEntry. This a data structure as defined here
RangeTblEntry , contains several fields describing the table entry relation, but we only need 2 fields from it.
typedef struct RangeTblEntry
{
char relkind; /* relation kind (see pg_class.relkind) */
Alias *eref; /* expanded reference names */
} RangeTblEntry;
relkind, used to specify the type of table we are trying to work on, the following shows that we only want to work with a table of RELKIND_RELATION that is ordinary table
if table_entry.relkind as u8 != RELKIND_RELATION {
continue;
}
we have different types of tables from ordinary, secondary, foriegn tables to regular tables you can find more in pg_class.h
let table_data = *table_entry.eref;
let name = CStr::from_ptr(table_data.aliasname);
we get the .eref, an Alias data structure containing an aliasname of the table. This name is converted from raw pointer to c char and then converted to a proper string reference. If this result table name matches our expected table name we set result to true else false
The is_contain_table can then be imported into src/lib.rs and then called inside the planner hook
fn planner(...) {
self.keep_running = utils::is_contain_table(parse.rtable, self.table.as_ref().unwrap());
if !self.keep_running {
return prev_hook(parse, query_string, cursor_options, bound_params);
}
}
if self.keep_running ends up being false, we call the prev_hook this to tell postgres to continue with its normal process.
Now we can confirm if our table is present in the query, let extract the column name and value from the query
fn planner(...) {
self.keep_running = utils::is_contain_table(parse.rtable, self.table.as_ref().unwrap());
if !self.keep_running {
return prev_hook(parse, query_string, cursor_options, bound_params);
}
let jointree = *parse.jointree;
let quals: *mut pg_sys::Node = jointree.quals;
let quals_node = eval_const_expressions(std::ptr::null_mut(), quals.cast());
let mut opexprs = vec![];
let mut boolexprs = vec![];
let mut result = None;
if is_a(quals_node.cast(), NodeTag::T_OpExpr) {
opexprs.push(quals_node.cast::<OpExpr>());
}
if is_a(quals_node.cast(), NodeTag::T_BoolExpr) {
boolexprs.push(quals_node.cast::<BoolExpr>());
}
}
Recall, we said that our main target is the quals Node in jointree, which contains the whereclause. The quals are fetched and then passed into eval_const_expressions, this is use to optimize the query, it use to reduce constant subexpression such as instead of the query having 2 + 2 it reduces it to 4
Once that is done, we need to identify the type of expression Node we are dealing with
e.g The following is OpExpr
Update Test SET description = 'animal fox' where title = 'Fox'
and the following is BoolExpr
Update Test SET description = 'animal fox' where title = 'Fox' AND id= 2
Hence is_a is used to check the type of Node expr we are dealing with, also note that this node is represented as NodeTag
fn planner(...) {
........
while let Some(boolexpr) = boolexprs.pop() {
let args = (*boolexpr).args;
let l = &(*args);
for i in 0..l.length {
let f = node_fetch(args, i as usize);
let t = f.cast::<Node>();
if is_a(t.cast(), NodeTag::T_OpExpr) {
opexprs.push(t.cast::<OpExpr>());
} else if is_a(t.cast(), NodeTag::T_BoolExpr) {
boolexprs.push(t.cast::<BoolExpr>());
}
}
}
}
For the query statement containing BoolExpr, within is is Opexpr so we loop through the BoolExpr, and fetch all the OpExpr until there is no BoolExpr to be evaluated.
Once we have the list of Opexpr needed, now is the type to search through Opexpr and its fields to get what we need
fn planner(....) {
........
for node in opexprs {
let op_expr_pointer = node.cast::<OpExpr>();
let op_expr = *op_expr_pointer;
let op_number = Oid::from(416);
// step 1
if op_expr.opno == op_number || op_expr.opno == Oid::from(TextEqualOperator) {
// step 2
let args = op_expr.args;
let argg = args.as_ref().unwrap();
let first_cell = argg.elements.add(0);
let first_value = first_cell.as_ref().unwrap().ptr_value;
let second_cell = argg.elements.add(1);
let second_value = second_cell.as_ref().unwrap().ptr_value;
let mut first_node = first_value.cast::<Node>();
let second_node = second_value.cast::<Node>();
// step 3
if is_a(first_node.cast(), pg_sys::NodeTag::T_RelabelType) {
let relabel = first_node.cast::<pg_sys::RelabelType>();
first_node = (*relabel).arg.cast::<pg_sys::Node>();
}
// step 4
if is_a(first_node.cast(), pg_sys::NodeTag::T_Var)
&& is_a(second_node.cast(), pg_sys::NodeTag::T_Const)
{
// final code goes here
}
}
}
result
}
Using the commented step to follow up on the code above
step 1 : OpExpr is a data structure describing the Operator expertion.
typedef struct OpExpr
{
Expr xpr;
Oid opno; /* PG_OPERATOR OID of the operator */
List *args; /* arguments to the operator (1 or 2) */
.....
} OpExpr;
Step 1 will check if the .opno is an equal operator which has an oid equivalent to 416 or it is Equal to TextEqualOperator which has an oid =98. You can view the list of the operator and their oid value in pg_operator.dat
step 2: We access the .arg which is a list of arguments to the operator, the List contains a field called elements this contains the actual data we need.
For example title="Fox" the elements data structure will store the argument like; {0=> 'title', 1=>"Fox"} so we can access them via the index. Note this is just a concrete example just to make sure the idea is fully passed since it is needed for the next explanation.
Once we access the .elements we access the ptr_value. note that elements is ListCell data structure. The ptr_value obtained for both first_value and second_value are then converted to a Node
step 3: Sometimes we might have a query statement like .... where column_integer = "2" The query process will need to do some kinda type conversion, it assigns this node to T_RelabelType and we then go ahead to cast it to the rightful node.
step 6: Check if the fist_node is a variable and check if the second_node is a constant node type.
Let’s fetch the variable first_node
fn planner(...) {
if is_a(first_node.cast(), pg_sys::NodeTag::T_Var)
&& is_a(second_node.cast(), pg_sys::NodeTag::T_Const)
{
let var: *mut pg_sys::Var = first_node.cast::<pg_sys::Var>();
let var_attid: i16 = var.as_ref().unwrap().varattno;
let varno = var.as_ref().unwrap().varno;
let rte = rt_fetch(varno, range_table);
let rte_relid = rte.as_ref().unwrap().relid;
let col_name = get_attname(rte_relid, var_attid, true);
let col_name_str = CStr::from_ptr(col_name).to_str().unwrap();
.......
}
}
Firstly, we cast first_node into Var expression node representing a variable, for our example the variable will be title
typedef struct Var {
Expr xpr;
Index varno; /* index of this var's relation in the range
* table, or INNER_VAR/OUTER_VAR/INDEX_VAR */
AttrNumber varattno; /* attribute number of this var, or zero for
* all attrs ("whole-row Var") */
........
}
First, we extract the .varno which is the index of the table in the rang table, and then .varttno which is the attribute number of the variable.
Using the index of the table .varno will get the table entry of the table itself using rt_fetch, using the table entry we can then obtain the Oid of the table using .relid. Having the table Oid and the attribute number of the variable we can then obtain the column name itself using get_attname
fn planner(...) {
if is_a(first_node.cast(), pg_sys::NodeTag::T_Var)
&& is_a(second_node.cast(), pg_sys::NodeTag::T_Const)
{
let constt: *mut pg_sys::Const = second_node.cast::<pg_sys::Const>();
let consstt = constt.as_ref().unwrap();
let const_cons = consstt.constvalue;
let const_type = consstt.consttype;
let mut foutoid: Oid = Oid::default();
let mut typisvarlena: bool = false;
getTypeOutputInfo(const_type, &mut foutoid, &mut typisvarlena);
let const_type_output = OidOutputFunctionCall(foutoid, const_cons);
let qual_value = CStr::from_ptr(const_type_output)
.to_str()
.expect("Failed to convert Postgres query string for rust");
}
}
Like the first_node, we cast the second_node into const data structure
typedef struct Const
{
Expr xpr;
Oid consttype; /* pg_type OID of the constant's datatype */
Datum constvalue; /* the constant's value */
.....
} Const;
Firstly, we extract constvalue which is a Datum, a postgres internal representation of the actual value, also we extract the consttype which is the Oid of the value data type. Datum can be used to represent any type of value ranging from float to integer and the likes, hence we need to properly get the details about the value data type using its Oid, hence a call to getTypeOutputInfo is needed.
Yes, we now have the data type information, and also the value Datum, next step is to make a call to OidOutputFunctionCall; every column data type is associated to a function responsible for the way the value of that data type is transformed from Datum.
What OidOutputFunctionCall does is to make a call to function manager fmngr that makes a call to the data type function and transforms them to the actual value from Datum. Once we have the actual value we convert it to a rust string CStr::from_ptr
Time to save the values obtained in our PRHook where_clause_receiver field
fn planner(...) {
......
if is_a(first_node.cast(), pg_sys::NodeTag::T_Var)
&& is_a(second_node.cast(), pg_sys::NodeTag::T_Const)
{
......
if col_name_str == key_column_name {
let s =
format!("PostgresRedis > The query qual is {col_name_str} = {qual_value}");
notice!("{s}");
self.where_clause_receiver = Some((String::from(col_name_str), qual_value.to_string()));
break;
}
}
}
We now have a redis key, we can now go ahead to fetch the redis value. View the full code for the planner hook here
Obtaining Redis Value - Executor End Hook
This article is about showing how we can update the redis store with a key and value while updating a specific table. Due to this, we need to add another hook method, to enable us to get the updated tuple.
impl PgHooks for PRHook {
fn executor_end(
&mut self,
query_desc: PgBox<pg_sys::QueryDesc>,
prev_hook: fn(query_desc: PgBox<pg_sys::QueryDesc>) -> pgrx::HookResult<()>,
) -> pgrx::HookResult<()> {
let op = query_desc.operation;
if op == CmdType_CMD_UPDATE {
}
}
}
We define the executor_end, the hook takes in query_desc which as type QueryDesc, a query descriptor; contains all the information needed to execute a query.
Firstly, we make a call to query_desc.operation to check the type of query that is executed. Once we identify that the command type is update we are set to go.
For the QueryDesc here are the fields we are going to need to fetch updated tuple:
typedef struct QueryDesc
{
CmdType operation; /* CMD_SELECT, CMD_UPDATE, etc. */
PlannedStmt *plannedstmt; /* planner's output (could be utility, too) */
/* These fields are set by ExecutorStart */
TupleDesc tupDesc; /* descriptor for result tuples */
EState *estate; /* executor's query-wide state */
PlanState *planstate; /* tree of per-plan-node state */
} QueryDesc;
our first mission, in the update, if block will be to make sure that our update command is not updating multiple rows, we just want to initialize our Postgres-redis process whenever an update is applied to a single row.
fn executor_end(
&mut self,
query_desc: PgBox<pg_sys::QueryDesc>,
prev_hook: fn(query_desc: PgBox<pg_sys::QueryDesc>) -> pgrx::HookResult<()>,
) -> pgrx::HookResult<()> {
let op = query_desc.operation;
if op == CmdType_CMD_UPDATE {
unsafe {
let mut single_row = false;
let estate = *(query_desc.estate);
if estate.es_processed == 1 {
single_row = true;
}
if single_row {
}
}
}
}
Dereferencing query_desc.estate we obtain the working state of the executor, this state is represented with Estate
The following show some of the fields of Estate we will need for our operation
typedef struct EState {
ResultRelInfo **es_result_relations; /* Array of per-range-table-entry
* ResultRelInfo pointers, or NULL
* if not a target table */
uint64 es_processed; /* # of tuples processed */
}
Using estate.es_processed we obtain the number of tuples processed which is equivalent to the number of rows updated. If number of row is one, we continue with our process
fn executor_end(
&mut self,
query_desc: PgBox<pg_sys::QueryDesc>,
prev_hook: fn(query_desc: PgBox<pg_sys::QueryDesc>) -> pgrx::HookResult<()>,
) -> pgrx::HookResult<()> {
.....
if single_row {
let result_rel_info = estate.es_result_relations;
if !result_rel_info.is_null() {
let relation_rel = *result_rel_info;
let relation_desc = (*relation_rel).ri_RelationDesc;
let tuple_new_slot = *((*relation_rel).ri_newTupleSlot);
}
}
}
Using estate.es_result_relations we access ResultRelInfo, this contains information about a result relation i.e contains information about our updated table.
Since estate.es_result_relations is a null pointer, we have to check if is not null and then we fully dereference the null pointer to access ri_RelationDesc which data reperesentation is a ReltionData; it holds the cached metadata of the table.
Whenever there is an update, postgres creates a new Tuple and then updates the old tuple by setting it to be invisible and then later runs a vacuum process to eradicate the old tuple. This is just a one-line summary of what the update process entails for more details about check interdb
*((*relation_rel).ri_newTupleSlot) is used to access the new tuple represented as TupleTableSlot.
fn executor_end(......) {
........
if !result_rel_info.is_null() {
..........
if !relation_desc.is_null() {
let relation_descp: pgrx::prelude::pg_sys::RelationData = *relation_desc;
let tuple_desc = PgTupleDesc::from_pg_unchecked(relation_descp.rd_att);
let natts = tuple_desc.natts;
for i in 0..natts {
let is_null = *tuple_new_slot.tts_isnull.add(i as usize);
if !is_null {
let desc_pointer = tuple_desc.attrs.as_ptr();
let desc_attr = *desc_pointer.add(i as usize);
let attr = desc_attr.name();
let value_pointer = *tuple_new_slot.tts_values.add(i as usize);
let mut foutoid: Oid = Oid::default();
let mut typisvarlena: bool = false;
let typoid: Oid = desc_attr.atttypid;
getTypeOutputInfo(typoid, &mut foutoid, &mut typisvarlena);
let output = OidOutputFunctionCall(foutoid, value_pointer);
let output_value = CStr::from_ptr(output);
let output_value = output_value
.to_str()
.expect("Failed to convert Postgres query string for rust");
if attr == expected_column {
self.update_receiver.value = Some(output_value.to_string())
self..update_receiver.value = attr.to_string();
}
}
}
}
relation_desc is a null pointer to the relation (table) cache entry, hence we need to confirm if it’s not null, after which we go ahead to dereference relation_desc, and then from relation_descp we obtain the tuple descriptor (describing each table rows) relation_descp.rd_att. The function from_pg_unchecked wraps the tuple descriptor TupleDesc into PgTupleDesc so has to monitor it reference count and drop it whenever the reference count is 0.
For our implementation we need to access a specific column to obtain the value to populate a defined redis key, to do that we need to loop through each tuples (rows) and get that specific column, hence we achieve this via tuple_desc.natts, where natts is the number of attributes in that tuple.
Looping through natts, first we check if the attribute we are about to access is valid and not null, if valid, we obtain the list of attributes from the tuple descriptor tuple_desc, and then using the current natt index we obtain the name of the attribute using let attr = desc_attr.name();
tuple_new_slot.tts_values contains per attribute values, using the natt index, we will fetch the attribute value, The atts_values.add(i) returns a Datum, recall that in the Planner hook we made mention of how to fetch the actual value of a Datum. And once the Dtaum is transformed we convert the result to a proper rust string.
Lastly, we check if the column name we fetched is equal to our expected column and we then the column name and its value in self.update_receiver
Background Process and Shared Memory
We need a way to communicate with our redis server, initialize the redis server, and send out the data we’ve gathered so far to redis.
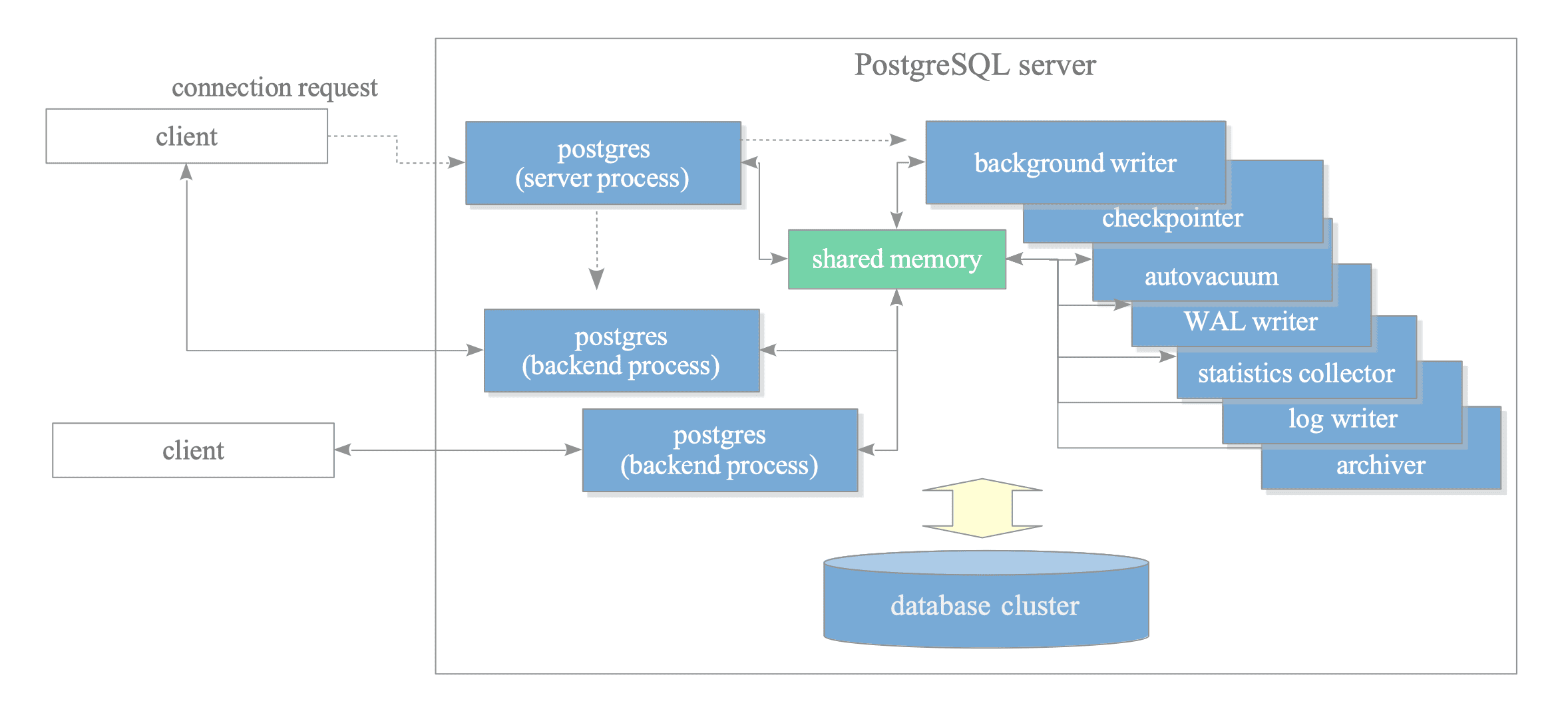
source. interdb
The image above shows the postgres process architecture. The process architecture shows that communication between processes is done via shared memory. The hooks we’ve created so far are in the backend process, including the data we’ve gathered are all available inside the backend process, to make the background writer have access to it, we need to save them in a shared memory. Also, why background writer, can’t we just call the redis server inside the background process, yes that’s possible, but we won’t want to spend more time executing a transaction and interfering with other transaction execution time.
To store the variables in shared memory we will follow the following steps:
- Create a struct type of how to save this data
- Impl shared memory trait for the struct type
- create a new method to create new info
- Create a Lock variable for the struct to manage how it is accessed concurrently
- Create utility functions to manage how data is added to the lock variable and also manage how it is managed
- Initialize it in our shared memory, to store the type in the shared memory
Create a file src/prshmem.rs for our shared memory code
use pgrx::{pg_guard, pg_shmem_init, prelude::*, shmem::*, warning, PGRXSharedMemory, PgLwLock};
// step 1
#[derive(Copy, Clone)]
pub struct Info {
pub key: [char; 127], // data is store on stack so size most be manually manage
pub value: [char; 127],
pub key_length: i8, // specify length to easily; access the key when needed
pub value_length: i8,
}
// step 2
unsafe impl PGRXSharedMemory for Info {
pub fn new(key_string: &str, value_string: &str) -> Info {
let mut key = [' '; 127];
for (i, c) in key_string.chars().enumerate() {
key[i] = c;
}
let mut value = [' '; 127];
for (i, c) in value_string.chars().enumerate() {
value[i] = c;
}
Info {
key,
key_length: key_string.len() as i8,
value,
value_length: value_string.len() as i8,
}
}
}
// step 3
pub static REDIS_BUFFER: PgLwLock<heapless::Vec<Info, 400>> = PgLwLock::new();
// step 4
pub fn move_redis_data() -> Vec<Info> {
let mut vec = REDIS_BUFFER.exclusive();
let r = vec.iter().copied().collect::<Vec<Info>>();
vec.clear();
r
}
pub fn add_item(item: Info) {
REDIS_BUFFER
.exclusive()
.push(item)
.unwrap_or_else(|_| warning!("Vector is full, discarding update"));
}
// step 5
pub fn init_redis_buffer() {
pg_shmem_init!(REDIS_BUFFER);
}
To create a Lock variable we make use of PgLwLock which is a rust wrapper for postgres LWlock which allows multiple readers to access the data, but a single writer at a time, and the writer must request exclusive access before updating the data. Hence in move_redis_data and add_item we make use a call to REDIS_BUFFER.exclusive() to have access.
pg_shmem_init function macro is used to initialize our newly created type in shared memory for later use.
Our shared memory variable is ready. another question will be, when and where should we make a call to store our data inside a shared memory, should we do that in executor_end hook? what if the query transaction fails for no reason before committing? how do we manage that? should we deal with Write-ahead-log?
To make the project not as complex as it should be, we decided to make use of the commit hook, with this hook we only make sure that data is only saved to shared memory when we are sure that the updated tuple is committed and also clear out the variable, once the transaction is aborted.
With this, we will update our hooks code in src/lib.rs
pub mod prshmem;
impl PgHooks for PRHook {
fn commit(&mut self) {
}
fn abort(&mut self) {
}
}
For commit hook, recall that we are saving the updated tuple data needed for redis value in self.update_receiver and we are storing the query statement args in self.where_clause_receiver, the process in commit hooks is to get the data from this variable and then store them in the shared memory
impl PgHooks for PRHook {
........
fn commit(&mut self) {
// step 1
if self.update_receiver.is_some() {
let update_receiver = self.update_receiver.as_ref().unwrap();
// step 2
let key_string = &(self.where_clause_receiver.as_ref().unwrap().1);
if update_receiver.value.is_some() {
let t = update_receiver.value.as_ref().unwrap();
// step 3
add_item(Info::new(key_string, t));
}
// step 4
self.update_receiver = None;
}
if self.where_clause_receiver.is_some() {
self.where_clause_receiver = None;
}
}
}
Here are the steps as shown in the code:
- check if
self.update_receiveris not empty - extract the value needed as a key from
self.where_clause_receiver - create an
Infonew struct and add it toREDIS_BUFFERusingadd_item - clear out
self.update_receiverandself.where_clause_receiver
For the abort hook we just need to check if the update_receiver and where_clauese_receiver are not empty and if so set them to None to make them empty
impl PgHooks for PRHook {
........
fn abort(&mut self) {
// Set all the objects to null if transaction aborts.
if self.update_receiver.is_some() {
self.update_receiver = None;
}
if self.where_clause_receiver.is_some() {
self.where_clause_receiver = None;
}
}
}
Share memory is now populated with our required data, we now need to call the background writer and make a call to redis. First, we need to initialize the Background writer in _PG_init
use pgrx::bgworkers::{BackgroundWorker, BackgroundWorkerBuilder, SignalWakeFlags};
#[pg_guard]
pub unsafe extern "C" fn _PG_init() {
.....
init_redis_buffer()
BackgroundWorkerBuilder::new("PGRedis Experiment")
.set_function("postgres_redis_background")
.set_library("postgres_redis")
.enable_shmem_access(None)
.load();
}
recall that in src/prshmem.rs we wrote a function init_redis_buffer to initialize shared memory without a new type. in _PG_init we make a call to it and also we create a Background worker with the name PGRedis Experiment and then we set the function this BackgroundWriter should manage which is postgres_redis_background.
We also make a call to set_library; this notifies the name of the shared library where the function managed by the background writer exists in. We then call .load to register the background writer and start it when needed
let’s update src/lib.rs, with the function managed by the background writer
#[pg_guard]
#[no_mangle]
pub extern "C" fn postgres_redis_background() {
// Step 1
BackgroundWorker::attach_signal_handlers(SignalWakeFlags::SIGHUP | SignalWakeFlags::SIGTERM);
log!(
"Hello from inside the {} BGWorker",
BackgroundWorker::get_name()
);
//step 2
if gucs::PGD_REDIS_URL.get().is_none() {
log!("Redis URL is not set");
return;
}
let url = gucs::PGD_REDIS_URL
.get()
.unwrap()
.to_str()
.expect("URL extraction failed");
// step 3
let client = redis::Client::open(url).unwrap();
let mut connection = client.get_connection().unwrap();
let mut pipe = redis::pipe();
// step 4
let delay = gucs::PGD_BG_DELAY.get() as u64;
while BackgroundWorker::wait_latch(Some(Duration::from_secs(delay))) {
// step 5
let results = move_redis_data();
for i in results.iter() {
let key: String = i.key[0..i.key_length as usize].iter().collect();
let value: String = i.value[0..i.value_length as usize].iter().collect();
log!("From bg: {key} => {value}");
pipe.set(key, value).ignore();
}
if results.len() > 0 {
let _: () = pipe.query(&mut connection).unwrap();
pipe.clear();
}
}
}
For the first step 1; we make a call to attach_signal_handlers, this helps postgres to handle the signal. for this we attach signals SIGHUP (signal sent to a process when its controlling terminal is closed) and SIGTERM (termination signal sent to a process, but allows the process to perform some cleanup before exiting). Postgres has a special signal handler that performs specific operations whenever this signal is received.
Step 2; we check if a redis URL PGD_REDIS_URL is configured and if yes, we extract the redis URL into a defined variable url
step 3; we initialize the redis connection
step 4: we fetch a configured delay time for our Background writer, normally postgres have a delay time to which a background writer is called after a successive call. We created the custom delay to manage the time when BackgroundWriter is called as we want. Note: that when discussing GUCS we never define the PGD_BG_DELAY, looking at the custom env variables we’ve created, try to create a new one for PGD_BG_DELAY
step 5; Firstly we fetch data from stored in Shared memory via move_redis_data and then loop through the data and send it to redis.
Running the code
We need to first update postgresql.conf and set the shared_preload_libraries = 'postgres_redis' . To get the location of the data directory for your current pgrx postgres server run the following
$ cargo pgrx run pg14
postgres_redis=# show data_directory;
data_directory
--------------------------
/Users/mac/.pgrx/data-14
(1 row)
Then you can locate the directory and then locate postgresql.conf to update the configuration, and here you can decide to set the config variables needed;
postgres_redis.redis_url = 'redis://localhost:6379'
postgres_redis.redis_table = 'test'
postgres_redis.key_column = 'title'
postgres_redis.value_column = 'description'
or you can use sql query to set the config and it will update postgresql.auto.conf
$ cargo pgrx run pg14
postgres_redis=# ALTER SYSTEM SET postgres_redis.key_column = 'title';
ALTER SYSTEM
postgres_redis=# ALTER SYSTEM SET postgres_redis.value_column = 'description';
ALTER SYSTEM
postgres_redis=# ALTER SYSTEM SET postgres_redis.redis_table = 'test';
Once all that is done we can now, initialize our extension
$ cargo pgrx run pg14
postgres_redis=# create extension postgres_redis;
CREATE EXTENSION
In the same terminal context let’s update a table
postgres_redis=# update test set description= 'updated for redis test' where title='Fox';
UPDATE 1
To confirm that everything is done properly, let’s check if redis contains the key value. We should expect redis to have a key Fox and a value updated for redis test
$ redis-cli
127.0.0.1:6379> GET Fox
"updated for redis test"
Conclusion
This being my first Rust and postgres extension, there was a lot to learn, especially when threading between C and Rust, I learned a lot about foreign function interface (FFI), how to cast between pointers and the like. This article only focuses on the postgres part and assumes you the reader have a rust knowledge.
We were able to delve into postgres and touch some of its internals; we got to see how to fetch updated tuples from postgres, convert Datum to the actual value, and handle query statements, and fetch data within query expressions.
Well, we never get to talk about handling select queries. To know about that and some of the retrospective designs for this project visit this link
The code source is available here